10·
1 month ago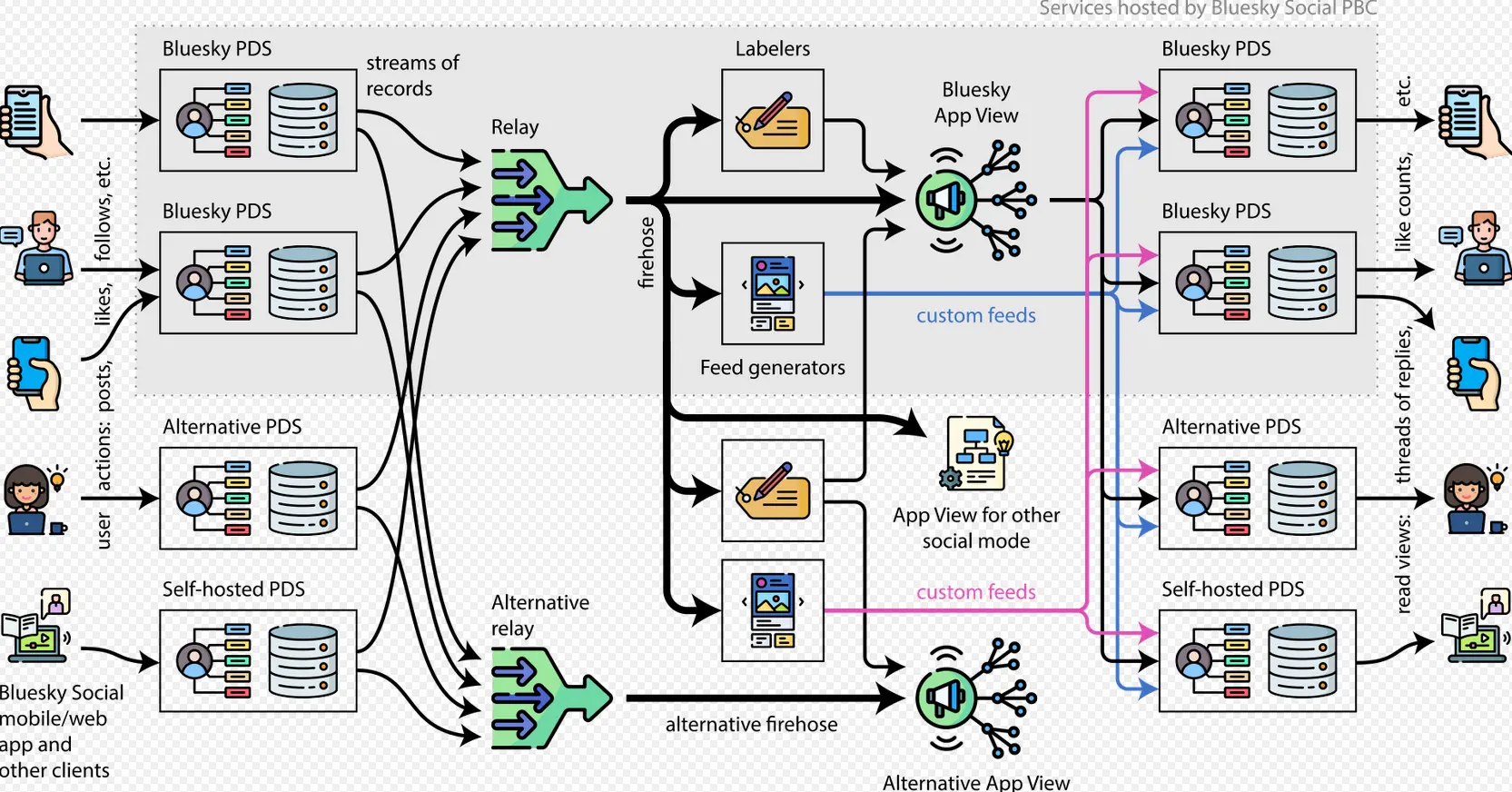
https://linktr.ee/tomawezome Donations:
Yes, assuming video content is stored across decentralized PDS instances
I tested it with “cat” and it blocks me from seeing things I’ve reposted with the word “cat” in it, so yeah it might! :)
A quick scroll of his account on Bluesky ( https://bsky.app/profile/urlyman.mastodon.social.ap.brid.gy ) makes it pretty clear why his Discover sucks. The algorithm on Bluesky sorta works like a mirror, you get out what you put in. My feed is all art posts and wholesome memes because I follow artists, creators, and comic pages, so it sounds like he’s trained his algorithm to be full of political complaining and toxic people like him. He should probably look into the Mute Words feature and start blocking stuff he thinks is toxic!
Bluesky is the first app built on the ATProtocol, its protocol for federation, sort of like how Mastodon was among the first to use ActivityPub after the overcomplexity of OStatus. The ATProtocol is a few years younger than ActivityPub, so its landscape isn’t fleshed out yet. Currently Bluesky caters more towards creators, artists, and social togetherness, whereas ActivityPub tends to lean harder into attracting techies. Both protocols can be run as independent instances, but most people are still using bsky.social for now until more instances pop up and federate together. The process for hosting a Bluesky instance is still undergoing development, but all features of it have been opened up. There exist multiple bridge systems that can interweave ActivityPub with ATProto.
https://github.com/bluesky-social/pds
https://whtwnd.com/bnewbold.net/entries/Notes on Running a Full-Network atproto Relay (July 2024)
Mobile games are designed like junk-food: take it out, eat some junk, then put it away to go do something else, throw away the bag or seal it for a quick snack later. Normal games are designed like a full meal: sit down somewhere with good atmosphere, nutritious, good conversation, get full and go home with plenty of leftovers and good memories
TinyLLM on a separate computer with 64GB RAM and a 12-core AMD Ryzen 5 5500GT, using the rocket-3b.Q5_K_M.gguf model, runs very quickly. Most of the RAM is used up by other programs I run on it, the LLM doesn’t take the lion’s share. I used to self host on just my laptop (5+ year old Thinkpad with upgraded RAM) and it ran OK with a few models but after a few months saved up for building a rig just for that kind of stuff to improve performance. All CPU, not using GPU, even if it would be faster, since I was curious if CPU-only would be usable, which it is. I also use the LLama-2 7b model or the 13b version, the 7b model ran slow on my laptop but runs at a decent speed on a larger rig. The less billions of parameters, the more goofy they get. Rocket-3b is great for quickly getting an idea of things, not great for copy-pasters. LLama 7b or 13b is a little better for handing you almost-exactly-correct answers for things. I think those models are meant for programming, but sometimes I ask them general life questions or vent to them and they receive it well and offer OK advice. I hope this info is helpful :)