
6·
5 days ago- Artist: The Beatles
- Album: Revolver
- Song: Tomorrow Never Knows
All of this user’s content is licensed under CC BY 4.0.

ELI5 How come it seems now the old [wives’] tale of Vietnamese eating pets and now its immigrants into the USA?
That’s still a rather incomprehensible sentence.
ELI5 How come it seems now the old wise tale of Vietnamese eating pets and now its immigrants into the USA?
I don’t understand that sentence.

Thank you! Solved!
Thank you for the information! Perhaps that’s what this setting is:
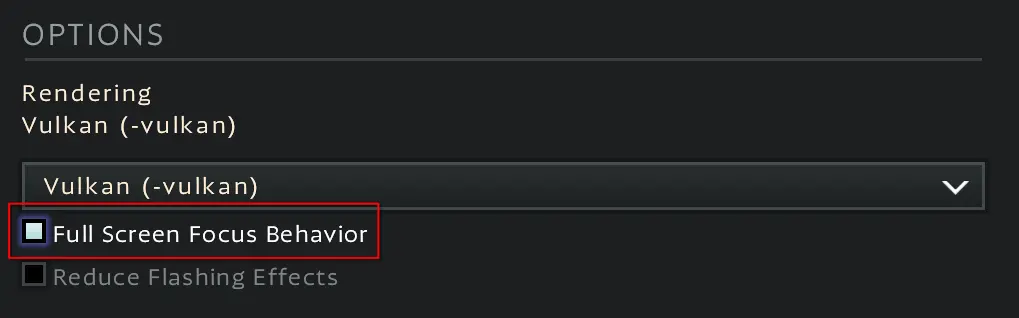
I will disable it and report back.
EDIT (2024-09-09T22:09Z): @ccf@lemmy.world, unfortunately, with that setting disabled, I still am experiencing the stuttering.
Make it work, then make it better.
I really like this one. It’s borderline a mantra.
As a counter to perfectionism:
If it’s worth doing, then it’s worth doing poorly. [source: a reddit user]

As of 2024-09-03T22:10:25.545Z, Starlink is now complying with Brazil’s X ban [1].
“We immediately initiated legal proceedings in the Brazilian Supreme Court explaining the gross illegality of this order and asking the Court to unfreeze our assets,” Starlink says in a post on X. “Regardless of the illegal treatment of Starlink in freezing of our assets, we are complying with the order to block access to X in Brazil.”
If this is a legitimate test, note that there is a community specifically for this purpose: !test@lemmy.ml.

Huh. That’s actually kind’ve a clever use case. I hadn’t considered that. I presume the main obstacle would be the token limit of whatever LLM that one is using (presuming that it was an LLM that was used). Analyzing an entire codebase, ofc, depending on the project, would likely require an enormous amount of tokens that an LLM wouldn’t be able to handle, or it would just be prohibitively expensive. To be clear, that’s not to say that I know that such an LLM doesn’t exist — one very well could — but if one doesn’t, then that would be rationale that i would currently stand behind.
The secret to success: survivorship bias.
I’m cringing at the date format “1-20-21”.
I’ve played it for a bit, and it’s a decently fun and well-made game! My only gripe is that it requires an email for signup; I wish it would only require a username and password. For most users, though, I’d wager that that’s a pretty minor issue.
I upgraded from 8GB to 16GB like 2 months ago.

The sound reminds me a lot of Mdou Moctar, but they have a lot of unique sounding effects going on. The grooves are really tight. They have a really cool look and atmosphere too. I’m really digging the subdued vocals; it’s interesting to see a more instrumental band that’s still using one’s voice as an instrument.
When I use a website as a source, at the time that I access it for information, I will also save a snapshot of it in the Wayback Machine. Ofc theres no guarantee that the Internet Archive will be able to survive, but the likelihood of that is probably far greater than some random website. So, if the link dies, one can still see it in the Wayback Machine. This also has the added benefit of locking in time what the source looked like when it was accessed (assuming one timestamps when they access the source when they cite it).
gestures passionately “Download Lemmy!”
I’m feeling warm and fuzzy for some reason.
deleted by creator
if you’re one of those who never liked using a cover now I bet you’re forced to use one because of the added vulnerability of the bump.
Laughs in case that still has a bump.










{kind=link}